Neural Networks Model Audience Reactions to Movies
July 21, 2017
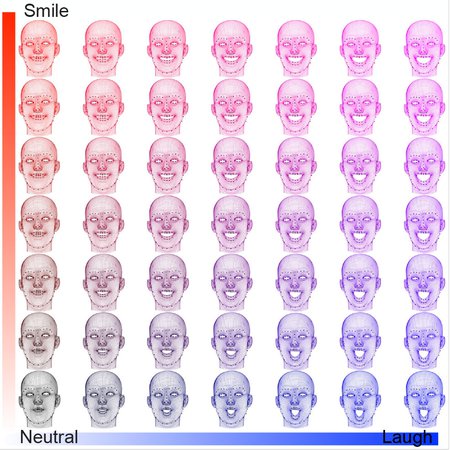 Yue's variational autoencoders translate images of faces into sets of numerical data using machine learning.
Credit: Courtesy of the Yisong Yue Laboratory/Caltech
Yue's variational autoencoders translate images of faces into sets of numerical data using machine learning.
Credit: Courtesy of the Yisong Yue Laboratory/Caltech

{kind=link}